
PDF OCR是一款国外的PDF电子书OCR文字识别软件,它的作用是从PDF文档中提取里面的文字内容,结果会保存到一个TXT文本文档中。工具栏包括的功能有上一页、下一页、滚到最前、滚到最后、放大、缩小、查看图像、OCR识别等等,需要识别PDF文档内容的网友可以下载PDF OCR绿色免费版使用。
基本介绍
PDF OCR基于OCR技术,可以快速,轻松地将扫描的PDF纸质书籍和文档转换为可编辑的电子文本文件。 PDF OCR有一个内置文本编辑器,允许您在没有MS Word的情况下编辑ocr结果文本。 PDF OCR还支持批处理模式,一次将所有pdf文件页面OCR转换为文本。 PDF OCR具有扫描图像到PDF转换器,这意味着您可以创建自己的扫描PDF书籍。
使用方法
1、下载并解压,双击“pdfOCRPortable.exe”打开软件,看到两个选项,我们点击左边的“Scanned PDF To Text”。

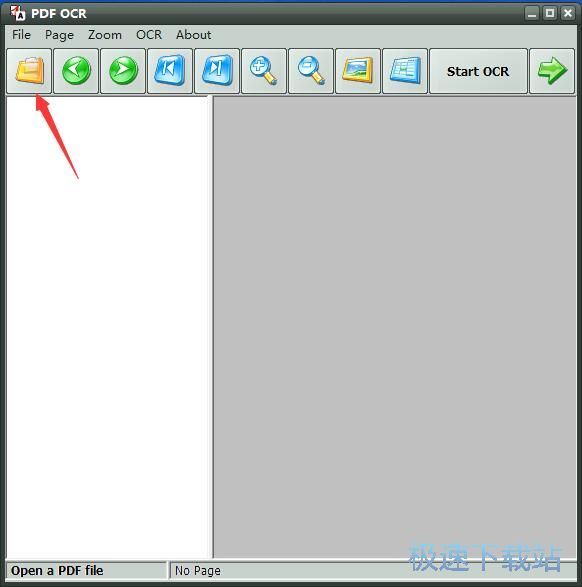
2、进入PDF OCR主界面,点击工具栏的文件夹图标。
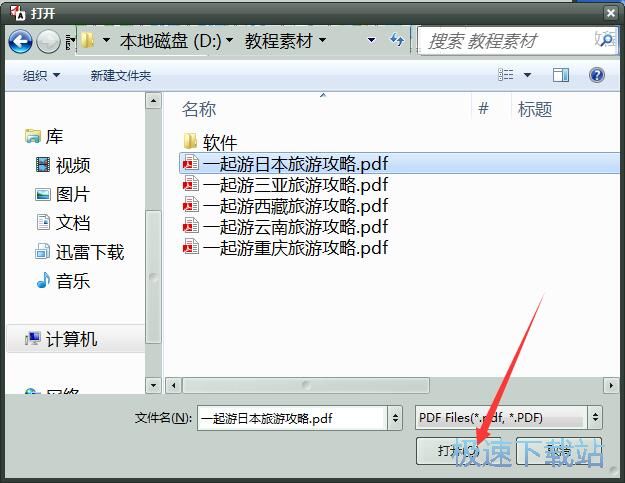
3、选择一个需要识别文字的PDF文档,点击打开。
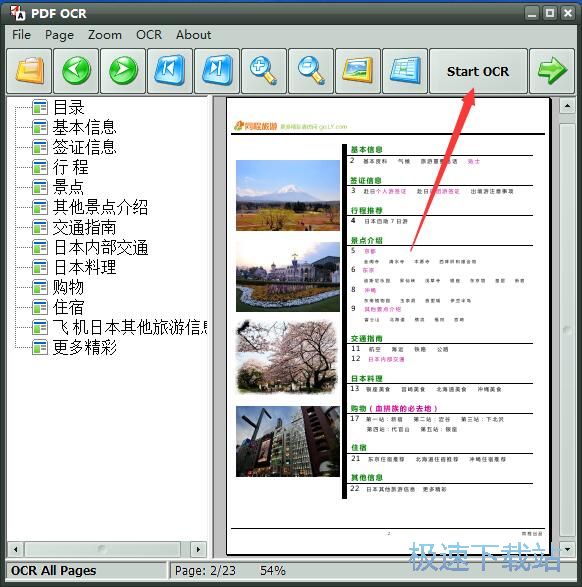
4、PDF文档打开成功,接着点击工具栏“Srart OCR”.
5、选择“OCR Current Page”,点击“Srart”。
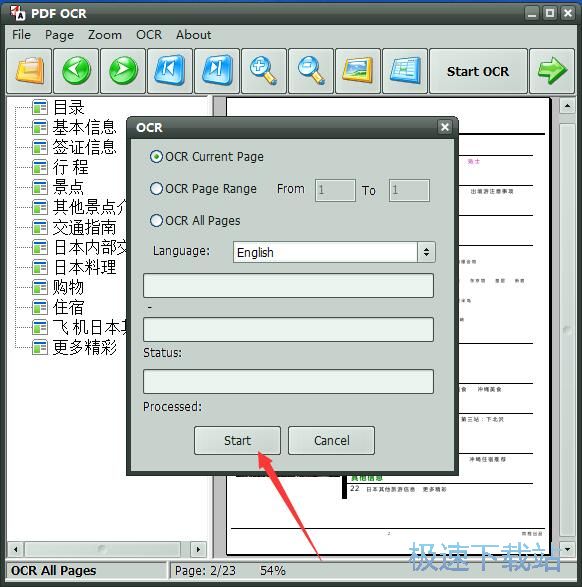
6、识别完成,会自动运行一个txt格式的文档,里面的内容就是从PDF里面提取出来的。
主要功能
功能可编辑 - 编辑扫描的PDF文档,如编辑文本文件!
功能轻松 - 只需2次点击即可将OCR PDF文本转换为文本。
功能快速 - PDF OCR具有快速OCR引擎,比其他OCR软件快92%。
功能页面选择 - 一次OCR单页,范围或所有页面。
功能支持超过10种语言 - 除英语外,PDF OCR还支持德语,法语,西班牙语,意大利语和其他语言。
软件特征
将扫描的PDF转换为文本
PDF OCR将扫描的PDF转换为文本,然后您可以编辑或使用PDF内容。
支持所有页面大小
PDF OCR支持A4,A3,B3,B4,B5和所有其他扫描页面大小。
将扫描图像转换为PDF文档
PDF OCR将扫描图像转换为PDF文档并创建扫描的PDF书籍。
使用方便
PDF OCR在3次点击内将PDF转换为文本。
OCR PDF快速
PDF OCR将在45秒内处理10多页。
内置文本编辑器
PDF OCR具有内置文本编辑器,允许您在不使用MS Word或写字板的情况下编辑ocr结果文本。
3 PDF PDF OCR模式
PDF OCR支持3种PDF OCR模式,单页,页面范围和所有页面ocr(批处理)。
支持10种语言
除英语外,PDF OCR还支持德语,法语,西班牙语,意大利语和其他语言。
文件信息
文件大小:539667 字节
文件说明:pdf OCR Portable Launcher
文件版本:2.2.0.0
MD5:44996FD640E46B50E3D5B56A28A86F67
SHA1:714F1E6CA1D99B0A63E876A40C4E058ACFBC45FF
CRC32:50440035
官方网站:https://www.pdfocr.net/index.html
相关搜索:OCR

997 KB / 2022/11/2

12.79 MB / 2022/10/30

123.8 MB / 2022/10/8

38.87 MB / 2022/9/22

37.2 MB / 2022/9/18

3.46 MB / 2022/9/7

759 KB / 2022/6/17

58.28 MB / 2022/6/15
- 共 0 条评论,平均 0 分 我来说两句
- 人气英雄联盟下载官方下载
- 《英雄联盟》(简称LOL)是由美国拳头游戏(Riot Games)开发、中国大陆地区腾讯游戏代理运营的英雄对战MOBA... [立即下载]
- 好评驱动精灵 9.61.3580.3002 标准版
- 电脑重新安装之前没有备份驱动,现在重装了之后所有驱动都没了?该怎么办才好?今天极速小编给大家推荐一款... [立即下载]
更多同类软件推荐
- 62565文本去重小工具 1.0 单文件版
- 32993文字查找助手 1.5 绿色版
- 24261虹吸墨Siphonink 2.7.0.7 中文版...
- 21047文本文件合并器 2.0 绿色免费版
- 20571秀米编辑器 2018 官方版
- 15060稿定设计 1.3.7
- 12079超级字符串批量替换工具 4.15 共...
- 8730福昕PDF编辑器 9.71.4.9480 中文...
- 7055UltraEdit 26.10.0.38 简体中文版...
- 6156猫图鹰 1.1.0 免费版