
选用Kettle开源ETL工具教程
时间:2019-08-20 17:34:08 作者:Dorise 浏览量:96
人们的生活水平逐渐提高,物质生活得到满足的同时,精神需求进而随之增加,电脑已经成为我们生活中和工作中不可缺少的一部分,电脑是由一些软件、系统、程序等组成,那么我们如果想要对电脑更好的使用,我们必须对这些有所了解,下面小编就带领大家一起来学习如何用Kettle开源ETL工具?
Kettle是一个Java编写的ETL工具,从4.2版本开始遵守Apache Licence 2.0协议,最新稳定版为7.1。。Kettle在2006年初加入了开源的BI公司Pentaho,正式命名为:Pentaho Data Integeration,简称“PDI”。自
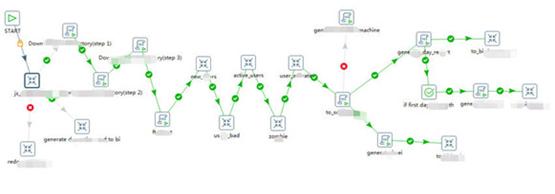
选用Kettle开源ETL工具教程图1
因为ETL属于偏底层的数据基础性工作,国内的项目甲方用户往往并不太懂这方面的具体需求和技术要求,因而也不太关注项目开发服务商使用了什么底层产品,对于这类数据产品在功能性、易用性、交换性能、数据实时性(最小延迟)、可靠稳定性、可运维管理性等方面缺乏具体的指标要求,通常不会要求通过严格的POC测试选型,再加上Kettle基础版是开源免费的,因此许多集成商/开发商在项目中为了想节省成本而盲目使用,结果往往是适得其反,造成了前期投入了相当大的开发人力成本及后期高昂的运维成本而达不到预期效果,骑虎难下。根据笔者二十多年的项目实施经验及大数据领域所面临的新要求,总结了选用kettle应注意的问题:
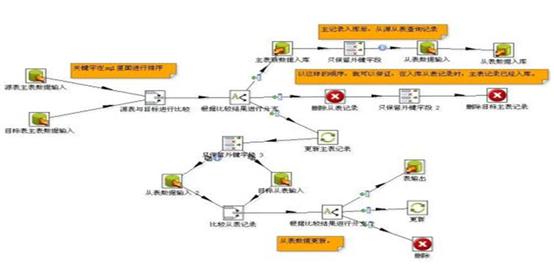
选用Kettle开源ETL工具教程图2
Kettle不支持实时数据同步场景。尽管kettle可以使用trigger方式获取表级的增量数据,但源端的应用系统方一般不会同意使用这种侵入性很强的方式,而且trigger方式无法保证事务复制的完整性和时间次序性。
Kettle交换性能往往达不到要求。由于kettle采用了二十多年前老旧的Java调用技术,在任务多、数据量大的场景下,往往消枆过大的计算资源,交换性能急剧下降,造成系统阻塞的状况出现。
Kettle对断点信息没有记录和保存,无法保证断点续传及数据不丢失等可靠性要求。
Kettle的ETL 处理流程与目标输出耦合性强,新的数据要求往往会造成处理流程的重新设计,灵活性差,导致时间周期和成本不断增加。新出现的ELT(把T-处理放在了末端数仓中处理)技术架构和方案,将抽取、加载过程与转换过程分开,并将所有需要的全量和实时增量数据快速加载至数仓,意味着在数仓结构设计中更具有灵活性来考虑新的变化需求,有利于项目的运维和管理,将项目的风险最小化。
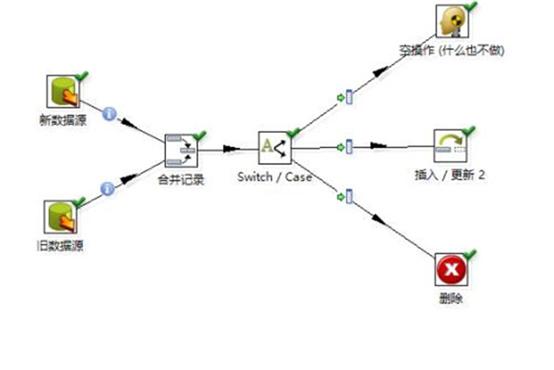
选用Kettle开源ETL工具教程图3
日益增加的异构数据源环境,包括各种关系型数据库、结构化及非结构化数据、以及NoSQL、MPP数据库/仓库和大数据平台Hadoop/Kafka的应用环境,Kettle缺乏对新数据源的有效支持能力。
免费版的Kettle缺乏必要的数据异常处理和监控运维等管理功能服务,项目开发商/服务商在项目成本及时间的约束下,难于满足这类管理功能需求,造成后续系统运维质量及用户满意度的下降。
在企业私有云和混合云的计算环境下,Kettle等传统产品的C/S架构难于满足构建云与边缘端的数据交换,并支持远程多用户共享使用的要求。
相关资讯
- 荔枝FM成立6年引来了新的纠纷?
- 10000单司机告诉你:滴滴也存在二八定律,怎...
- 炸弹小分队玩法详解 对战小技巧汇总
- 在美柚APP上广告推行投进是怎样做的?
- 手把手教你如何用“天眼查”第一时间发掘短...
- B612——带给你童话感觉的自拍神器
- 携程网怎么抢低价机票 携程抢低价机票技巧
- 知乎里边的小技巧,把握这些你就能轻松做推...
- 如何用作业帮快速寻找答案
- 美团小技巧、你学到了吗?
- 国内地图APP哪个好?高德、百度和腾讯对比测...
- 选用Kettle开源ETL工具教程
- linux服务器搭建教程
- PDF数字界的纸张:科普向
- office Acc Microsoft ess的特性教程
- 最权威“化妆品监管”APP来了!备案、许可、...
- 打开Airbnb爱彼迎2019的正确方法
- 如何更好的使用PDF: 用预览合并技巧
- 如何更好的使用PDF:互联性最高的Acrobat
- 国内地图APP哪个好?高德、百度和腾讯对比测...