
如何更好的使用PDF:复制中的文字重复问题(2)
时间:2019-08-20 18:51:19 作者:johnnyl 浏览量:41
另一方面, U+2F2F 的全名是「Kangxi Radical Work」,其所在区块是「Kangxi Radicals」(康熙字典部首)。换句话说,两个「工」虽然长得一模一样,但身份并不相同,一个是汉字,另一个是部首。
这样一来,我们也就知道预览 app 是怎么复制出「重复」的文字了。
实际上,它并没有复制出来两个一样的「工」字,而是同时复制出来了两个不同的字符——前一个是作为部首的「工」,后一个才是真正的汉字「工」。将预览的复制结果粘贴到 文本转 Unicode 编码工具 里,就能看得很明显:
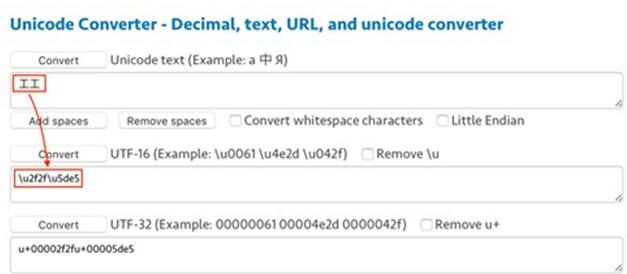
.如何更好的使用PDF:复制中的文字重复问题图六
不过,PDF 为什么要在 CMap 中作这样「一对多」的映射呢?的确,从预览 app 的角度看,它或许还有理由感到一点小委屈:我做错了什么,PDF 明明告诉我这是两个字啊?
回答这个问题,就要先了解「康熙字典部首」区块中的字符的用途。对此,这个网页 解释得很清楚:

.如何更好的使用PDF:复制中的文字重复问题图七
既然全部部首的字元都在另一个地方编了码,那么为何要再次编码呢?据统一码(即 Unicode——笔者注)的文件指出,本区块的字元只作部首之用,不应该当作一般文字用途,文件更进一步提出,必要时甚至可以用不同的字型格式,表明是属于本区块的字元。换句话说,例如编辑一本字典,部首页、部首标题和「参见某部若干画」等文字,都应使用本区块内的字元;而内文和字头、词条等文字部分,则应使用「中日韩统一表意文字区块」中的字元。这样做的原意,是希望让机器知道该字元现时所充当的角色:是「一般文字」,还是「部首文字」。当然,这些分别对人类来说可能没有作用,但对机器的语意分析是十分重要的。
实际上,类似的需求在使用拉丁字符的语言中同样存在。最典型的是西文排版中所谓 「合字」(ligature)的概念,即针对 ff、fi 这样笔画容易「打架」的字符组合,将其当作一个整体来专门设计造型。因此,这些字符组合在 Unicode 中需要有独立的码位,如 ff (U+FB00)、fi (U+FB01) 等(请试着动手复制一下这些字符)。可是,合字在显示时是一个整体,而在复制和搜索时却要看作两个独立的字符。而在 PDF 中,合字的这种双重身份也正是通过 CMap 的「一对多」映射实现的。
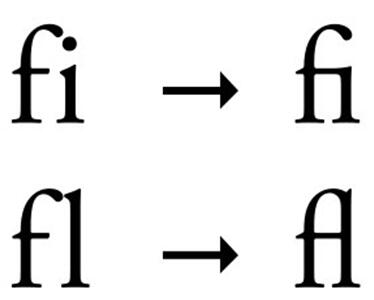
.如何更好的使用PDF:复制中的文字重复问题图八
因此,复制文字重复的故障,其责任并不在于 PDF 的编码。「一对多」的映射并不是一种冗余或者混淆,而是为了适应机器和用户的不同需要而必须加入的特殊处理。说到底,还是预览 App 的优化功夫没下到家,没有意识到 PDF 文本在显示、复制、搜索时应该受到不同的对待。这也再次应证了我之前文章中的一个观点:PDF 阅读器很多时候拼的不是功能有多丰富(反正都拼不过亲儿子 Acrobat),而是能不能做好复制、搜索这些基础功能的细节。
相关资讯
相关软件

56.69 MB / 2019/4/23

13.61 MB / 2019/5/25

123.8 MB / 2019/5/24

53.92 MB / 2018/2/1
13.45 MB / 2016/10/8
51.32 MB / 2018/7/21
3.59 MB / 2017/6/15

9.32 MB / 2019/6/10
- 荔枝FM成立6年引来了新的纠纷?
- 10000单司机告诉你:滴滴也存在二八定律,怎...
- 炸弹小分队玩法详解 对战小技巧汇总
- 在美柚APP上广告推行投进是怎样做的?
- 手把手教你如何用“天眼查”第一时间发掘短...
- B612――带给你童话感觉的自拍神器
- 携程网怎么抢低价机票 携程抢低价机票技巧
- 知乎里边的小技巧,把握这些你就能轻松做推...
- 如何用作业帮快速寻找答案
- 美团小技巧、你学到了吗?
- 如何更好的使用PDF:复制中的文字重复问题
- 如何更好的使用PDF:PDFelement安全强大
- 如何更好的使用PDF:Preview
- 优酷终于迎来爆款,距离腾讯爱奇艺还有多远...
- 微信:微信记录终于可以找回了
- 国内地图APP哪个好?高德、百度和腾讯对比测...
- 选用Kettle开源ETL工具教程
- linux服务器搭建教程
- PDF数字界的纸张:科普向
- office Acc Microsoft ess的特性教程