
ABBYY FineReader 14图像处理使用方法
时间:2017-05-11 11:27:09 作者:不思议游戏 浏览量:44

图像处理选项可提高源图像的质量,便于准确地识别光学字符。扫描纸质文档或从图像文件创建 PDF 时,务必要选择合适的图像处理选项。作为功能强大的OCR文字识别软件,和ABBYY FineReader 12一样,ABBYY FineReader 14也有图像处理的功能,能够自动帮助用户消除普通扫描和数码照片的缺陷。

在ABBYY FineReader 14中自定义扫描和打开页面,你可以:
•启用/禁用PDF编辑器中的背景识别;
•当添加页面到OCR编辑器中时,启用/禁用页面的自动分析和识别;
•指定图像预处理设置。
你可以在‘新建任务’窗口中打开PDF文档、图像或扫描件时选择想要的选项,也可以在‘选项’对话框(工具 > 选项)的‘图像处理’选项上选择想要的选项。
注意:在选项对话框中所做的任何更改将只应用到最新扫描或打开的图像。
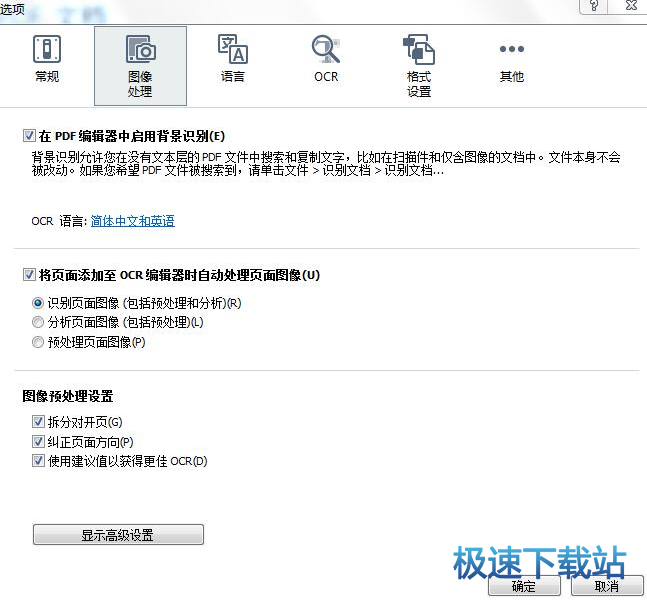
选项对话框里的图像处理选项包含以下选项:
1、在PDF编辑器中启用背景识别
背景识别将用于你在PDF编辑器中打开的所有页面,背景识别允许用户在没有文本层的PDF文件中搜索并复制文本,比如只包含扫描件或从图像创建的文档,文档本身不会有永久性的改动。
在该选项上,还可以指定OCR语言。
如果你希望其他用户也能在该文档里执行文本搜索,可以点击文件 > 识别文档 > 识别文档。
2、将页面图像添加至OCR编辑器时自动处理图像
默认情况下,页面会自动分析和识别,但你可以改变这种行为,以下模式可以使用:
•识别页面图像(包括预处理和分析)
当图像在OCR编辑器中打开时,它们会使用‘图像预处理设置’组中选定的设置自动预处理,分析和OCR同样自动执行。
•分析页面图像(包括预处理)
图像预处理和文档分析自动执行,但OCR过程必须手动开始。
•预处理页面图像
只有预处理是自动完成的,分析和OCR必须手动开始,这种模式常用于带有复杂结构的文档。
如果你不希望添加的图像自动处理,则清除‘将页面图像添加至OCR编辑器时自动处理图像’选项。
这可以让你快速打开较大的文档,只识别文档里选中的页面,并将文档保存为图像。
ABBYY FineReader 16.0.0.328 官方版
- 软件性质:国产软件
- 授权方式:注册版
- 软件语言:简体中文
- 软件大小:413524 KB
- 下载次数:455 次
- 更新时间:2019/4/8 19:37:22
- 运行平台:Win7,Win8,Win10,...
- 软件描述:ABBYY FineReader 14是一种OCR图片文字识别软件。它提供快速、... [立即下载]
相关资讯
相关软件

1033.68 MB / 2017/7/10

320 KB / 2017/7/4

47.8 MB / 2017/6/20

11.63 MB / 2017/8/2

196.28 MB / 2018/10/9

403.83 MB / 2018/8/15

20 MB / 2019/3/26

4.58 MB / 2014/9/16
- 怎么将网易云音乐缓存转换为MP3文件?
- 比特精灵下载BT种子BT电影教程
- 土豆聊天软件Potato Chat中文设置教程
- 怎么注册Potato Chat?土豆聊天注册账号教程...
- 浮云音频降噪软件对MP3降噪处理教程
- 英雄联盟官方助手登陆失败问题解决方法
- 蜜蜂剪辑添加视频特效教程
- 比特彗星下载BT种子电影教程
- 好图看看安装与卸载
- 豪迪QQ群发器发送好友使用方法介绍
- 生意专家教你如何做好短信营销
- 怎么使用有道云笔记APP收藏网页链接?
- 怎么在有道云笔记APP中添加文字笔记
- 怎么移除手机QQ导航栏中的QQ看点按钮?
- 怎么对PDF文档添加文字水印和图片水印?
- 批量向视频添加文字水印和图片水印教程
- APE Player播放APE音乐和转换格式教程
- 360桌面助手整理桌面图标及添加待办事项教程...
- Clavier Plus设置微信电脑版快捷键教程
- 易达精细进销存新增销售记录和商品信息教程...









