
您的位置:极速下载站 → 电脑软件 → 应用程序 → 文字处理 → VeryPDF Screen OCR
VeryPDF Screen OCR是一款由国外VeryPDF软件推出的OCR图片文字识别工具,它可以帮你识别图片里面的文字,成功率非常高,识别完成后可以直接对文字进行复制,支持历史记录功能,就是说所有识别过的图片都会保存下来,方便你随时找回并进行识别,需要的网友可以下载VeryPDF Screen OCR官方版试用。
VeryPDF Screen OCR是一款智能屏幕捕获工具和字符识别器。您可以使用此应用程序从屏幕中选择任何部分,识别文本,并以TXT格式保存字符。 VeryPDF屏幕OCR可以从屏幕上显示的扫描PDF页面,图像,受保护的网页,对话框,图标等中提取字符,以获得可编辑和可搜索的数据。
主要功能
捕获屏幕并保存到图像。
识别屏幕上显示的文本。
识别现有图像中的文本。
使用方法
1、下载并解压,双击 [verypdfscreenocr.exe] 安装软件。
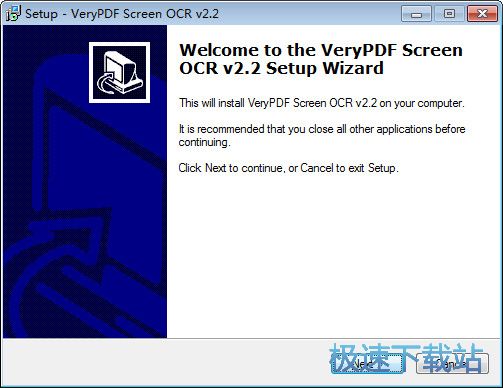
2、点击Capture捕获。
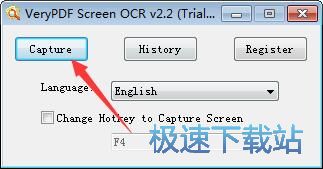
3、这时候出现一个类似QQ截图的选区,选择一个要识别的区域,双击鼠标左键。
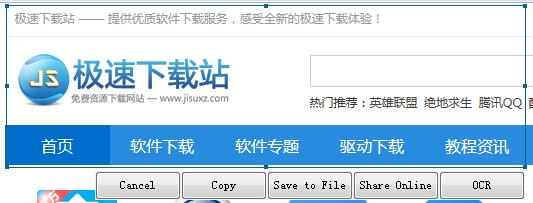
4、识别完成,左边可以看到图片,右方是识别出来的文字。
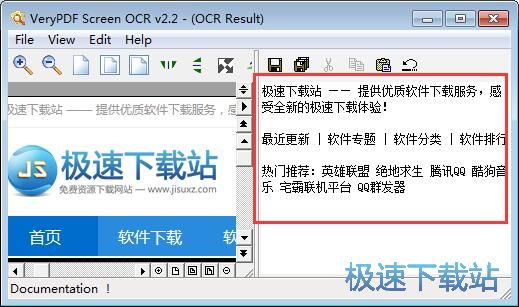
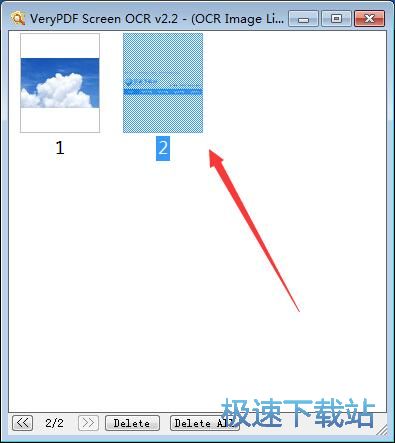
5、这是历史窗口,选择即可找回之前识别的内容,也可以进行删除操作。
主要特点
识别所选区域中的文本
VeryPDF屏幕OCR能够识别计算机屏幕上任何选定区域中的文本,包括无法用鼠标突出显示的区域。 VeryPDF Screen OCR使您可以将屏幕上任何位置的任何角色转换为可编辑和可搜索的文本。

识别屏幕上的多语言文本
VeryPDF屏幕OCR支持多种语言,包括英语,法语,丹麦语,德语,意大利语,荷兰语,西班牙语,葡萄牙语,希腊语,越南语,中文,保加利亚语,加泰罗尼亚语,匈牙利语,印度尼西亚语等.EveryPDF Screen OCR能够识别多种语言的文本。

识别现有图像中的文本
除了识别屏幕快照中的文本外,VeryPDF屏幕OCR还能够识别计算机上现有图像中的文本。用户可以将这些图像导入进程队列,并使用应用程序识别图像中的文本,就像屏幕快照一样。

软件特征
能够识别计算机屏幕上任何区域中显示的字符。
识别任何扫描文件中的字符,并将其转换为可编辑的文本。
捕获阻止被复制的网页上的文本。
能够识别英语,法语,丹麦语,德语,意大利语,荷兰语,西班牙语,葡萄牙语,希腊语,越南语,中文,保加利亚语,加泰罗尼亚语,匈牙利语等文本。
自动将屏幕快照和已识别的文本保存在计算机上。
能够将捕获的屏幕截图复制到剪贴板。
能够与其他人在线共享捕获的屏幕快照。
提供菜单项以查看已保存图像的目录。
允许您查看屏幕截图和文本内容的历史记录。
选项将屏幕截图保存在磁盘上并将路径复制到剪贴板。
能够自定义热键捕获。
系统启动后自动运行的选项。
文件信息
文件大小:17044813 字节
文件说明:VeryPDF Screen OCR v2.2 Setup
MD5:6403A8340A0EE875AB6B96D114BFE25B
SHA1:FB480298F440386FB7C0C98C052BF2D023884FC4
CRC32:F9483D0B

342 KB / 2020/2/5

1.02 MB / 2020/2/4

102.78 MB / 2020/2/2

1 KB / 2020/1/31

5.54 MB / 2020/1/31

570 KB / 2020/1/30

16.15 MB / 2020/1/30

53.82 MB / 2020/1/29
- 共 0 条评论,平均 0 分 我来说两句
- 人气英雄联盟下载官方下载
- 《英雄联盟》(简称LOL)是由美国拳头游戏(Riot Games)开发、中国大陆地区腾讯游戏代理运营的英雄对战MOBA... [立即下载]
- 好评谷歌浏览器 75.0.3770.75 官方版
- 谷歌浏览器(英文名称: Google Chrome)是一款由全球比较快、比较安全、比较好用的网页浏览器软件,由全球... [立即下载]